

Results 3,121 to 3,130 of 12094
Thread: Anandtech News
-
07-02-13, 10:01 AM #3121
Anandtech: Gigabyte Haswell Motherboard Giveaway
Hot on the heels of Intel's Haswell launch, Gigabyte was kind enough to share two of its flagship 8-series motherboards to give away to some lucky AnandTech readers. Today's giveaway includes one Gigabyte G1.Sniper 5 and one Z87X-OC.
More...
-
07-02-13, 12:30 PM #3122
Anandtech: Razer Blade 14-Inch Gaming Notebook Review
While their 17" gaming system has seen steady and incremental improvement, new to the Razer lineup is a notebook with all of the gaming performance in a remarkably slim 14" chassis. Could this be even better than the full size Razer Blade Pro?
More...
-
07-02-13, 09:30 PM #3123
Anandtech: Kinesis Advantage Review: Long-Term Evaluation
Round two of our ergonomic keyboard coverage brings us the Kinesis Advantage. Earlier this year, I reviewed the TECK—the Truly Ergonomic Computer Keyboard—one of the few keyboards on the market that combines an ergonomic layout with mechanical Cherry MX switches. As you’d expect, that review opened the door for me to do a couple more ergonomic keyboard reviews.
More...
-
07-03-13, 09:30 AM #3124
Anandtech: Trials of an Intel Quad Processor System: 4x E5-4650L from SuperMicro
Trials of an Intel Quad Processor System: 4x E5-4650L from SuperMicro
In recent months at AnandTech we have tackled a few issues of dual processor systems for regular use, and whether having a dual processor system as a theoretical scientist may help or hinder various benchmark scenarios. For the problems that I encountered as a theoretical physical chemist, using a dual processor system without any form of formal training dealing with memory allocation (NUMA) resulted in a severe performance hit for anything that required a significant level of memory accesses, especially grid solvers that required pluuing information from large arrays held in memory. Part of the issue was latency access dealing with data that was in the memory of the other CPU, and thus a formal training in writing NUMA code would be applicable for multi-processor systems. Nevertheless in my AnandTech testing we did see significant speedup when dealing with various ‘pre-built’ software scenarios such as video conversion using Xilisoft Video Converter, rendering using PovRay and our 3D Particle Movement Benchmark.
To take this testing one stage further, SuperMicro kindly agreed to loan me remote desktop access to one of their internal quad processor (4P) systems. The movement from 2P to 4P is almost strictly in the realms of business investment, except for a few Folding@home enthusiasts that have seen large gains moving to a quad processor AMD system using obscure buyers for motherboards and eBay for processors. But with 4P in the business realm, the software has to match that usage scenario and scale appropriately.
Our testing scenario will cover our server motherboard CPU tests only – as I only had remote desktop access I was not fortunate enough to do any ‘gaming’ tests, although our gaming CPU article may have shown that unless you are doing a massive multi-screen multi-GPU setup then anything more than a single Sandy Bridge-E system may be overkill.
Test Setup:
Supermicro X9QR7-TF+
4x Intel Xeon E5-4650L @ 2.6 GHz (3.1 GHz Turbo), 8 cores (16 threads) each
Kingston 128GB ECC DDR3-1600 C11
Windows Server Edition 2012 Standard
Issues Encountered
As you might imagine, moving from 1P to 2P and then to 4P without much experience in the field of multi-processor calculations was initially very daunting. The main issue moving to 4P was having an operating system that actually detected all the threads possible and then communicated that to software using the Windows APIs. In both Windows Server 2008 R2 Standard and 2012 Standard, the system would detect all 64 threads in task manager, but only report 32 threads to software. This raises a number of issues when dealing with software that automatically detects the number of threads on a system and only issues that number. In this scenario the user would need to manually set the number of threads, but it all depends on the way the program was written. For example, our Xilisoft and 3DPM tests do an automatic thread detection but set the threads to what is detected, whereas PovRay spawns a large number of threads despite automatic detection. Cinebench as well detected half the threads automatically, but at least has an option to spawn a custom number of threads.
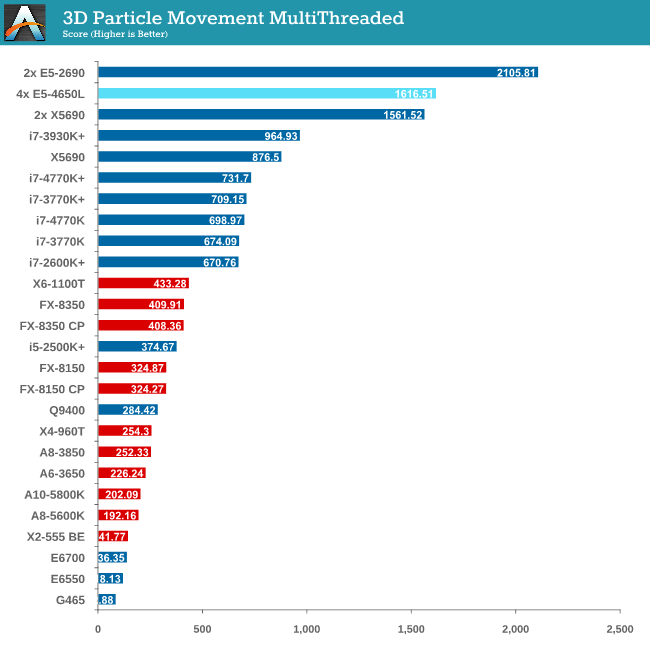
Point Calculations - 3D Movement Algorithm Test
The algorithms in 3DPM employ both uniform random number generation or normal distribution random number generation, and vary in various amounts of trigonometric operations, conditional statements, generation and rejection, fused operations, etc. The benchmark runs through six algorithms for a specified number of particles and steps, and calculates the speed of each algorithm, then sums them all for a final score. This is an example of a real world situation that a computational scientist may find themselves in, rather than a pure synthetic benchmark. The benchmark is also parallel between particles simulated, and we test the single thread performance as well as the multi-threaded performance.
The 3DPM test falls under the half-thread detection issue, and as a result of the high threads but lower single core speed we only just get an improvement over a 2P Westmere-EP system. For single thread performance the single thread speed of the E5-4650L (3.1 GHz) is too low to compete with other Sandy Bridge and above processors.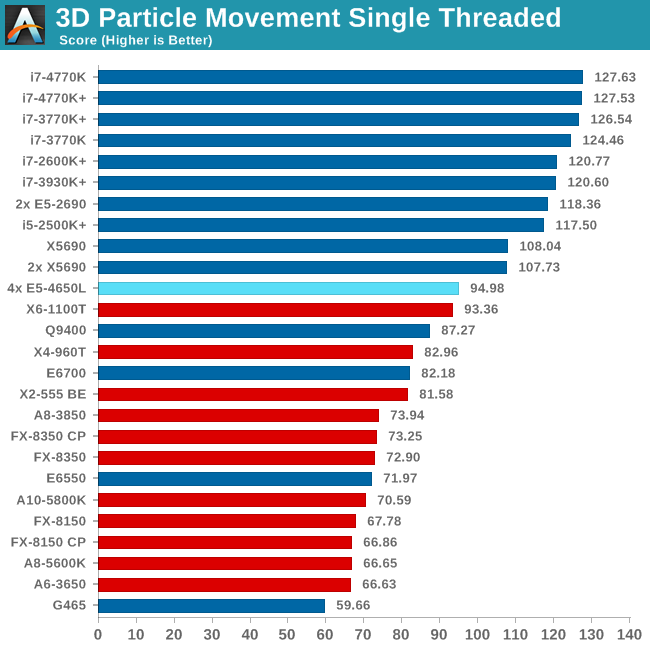
Compression - WinRAR 4.2
With 64-bit WinRAR, we compress the set of files used in the USB speed tests. WinRAR x64 3.93 attempts to use multithreading when possible, and provides as a good test for when a system has variable threaded load. WinRAR 4.2 does this a lot better! If a system has multiple speeds to invoke at different loading, the switching between those speeds will determine how well the system will do.
As WinRAR is ultimately dependent on memory speed, the 1600 C11 runs into the issues that the lower memory speed situations face. Despite this, the 2P Westmere-EP system still wins hands down.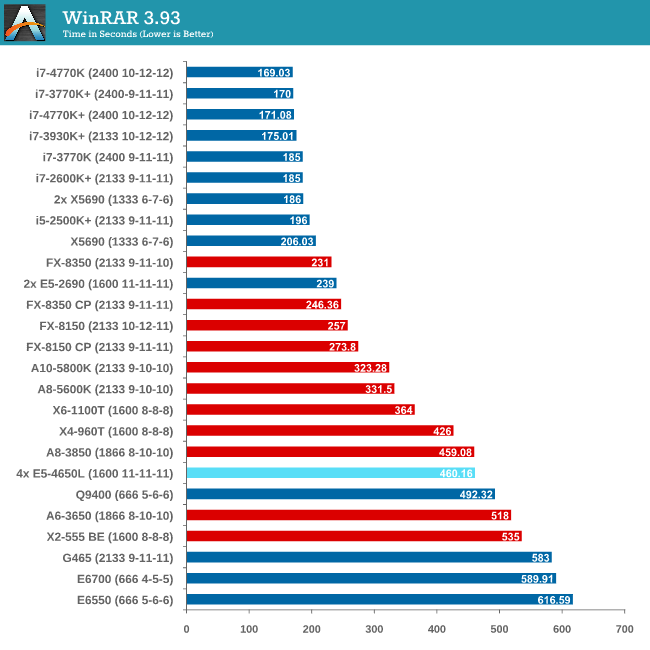
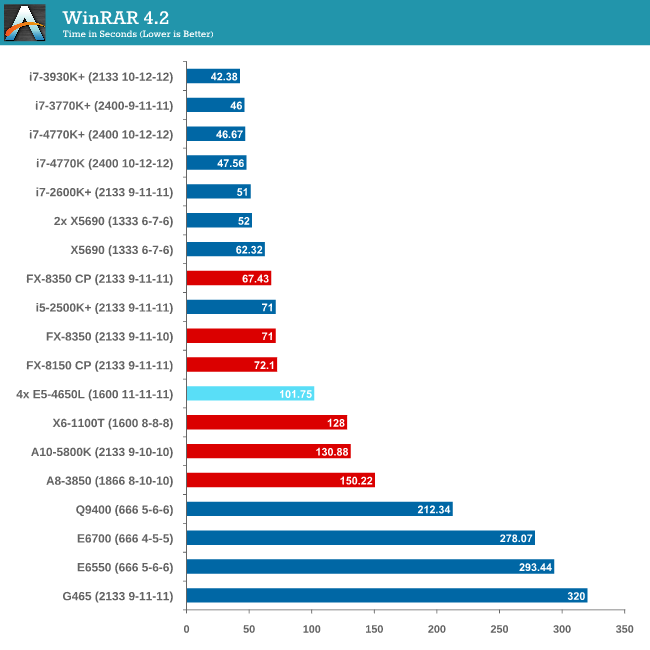
Image Manipulation - FastStone Image Viewer 4.2
FastStone Image Viewer is a free piece of software I have been using for quite a few years now. It allows quick viewing of flat images, as well as resizing, changing color depth, adding simple text or simple filters. It also has a bulk image conversion tool, which we use here. The software currently operates only in single-thread mode, which should change in later versions of the software. For this test, we convert a series of 170 files, of various resolutions, dimensions and types (of a total size of 163MB), all to the .gif format of 640x480 dimensions.
MHz and IPC wins for FastStone, which the single thread speed of the E6-4650s do not have.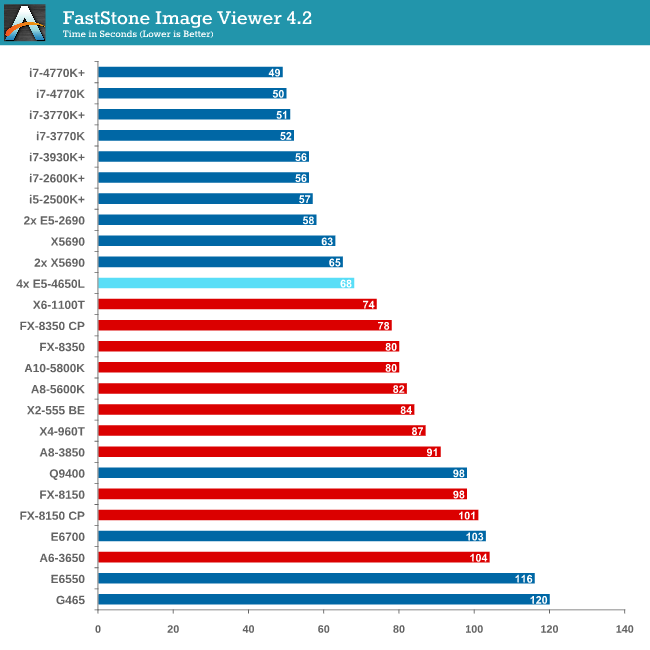
Video Conversion - Xilisoft Video Converter 7
With XVC, users can convert any type of normal video to any compatible format for smartphones, tablets and other devices. By default, it uses all available threads on the system, and in the presence of appropriate graphics cards, can utilize CUDA for NVIDIA GPUs as well as AMD WinAPP for AMD GPUs. For this test, we use a set of 33 HD videos, each lasting 30 seconds, and convert them from 1080p to an iPod H.264 video format using just the CPU. The time taken to convert these videos gives us our result.
Due to the nature of XVC we do not see any speed up against Westmere-EP due to the 33rd video only being assigned a single thread, essentially doubling the time of the conversion.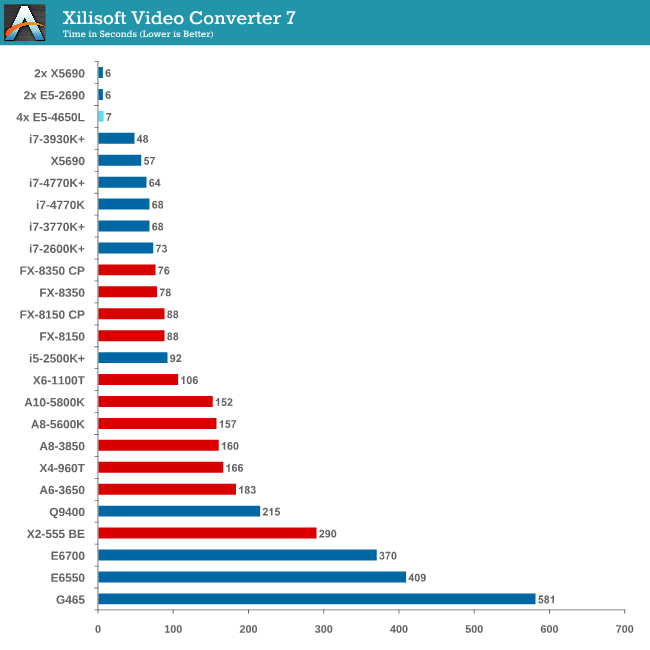
Rendering – PovRay 3.7
The Persistence of Vision RayTracer, or PovRay, is a freeware package for as the name suggests, ray tracing. It is a pure renderer, rather than modeling software, but the latest beta version contains a handy benchmark for stressing all processing threads on a platform. We have been using this test in motherboard reviews to test memory stability at various CPU speeds to good effect – if it passes the test, the IMC in the CPU is stable for a given CPU speed. As a CPU test, it runs for approximately 2-3 minutes on high end platforms.
PovRay is the first benchmark that shows the full strength of 64 Intel threads, scoring almost double that of the 24 thread Westmere-EP system (which was at higher frequency).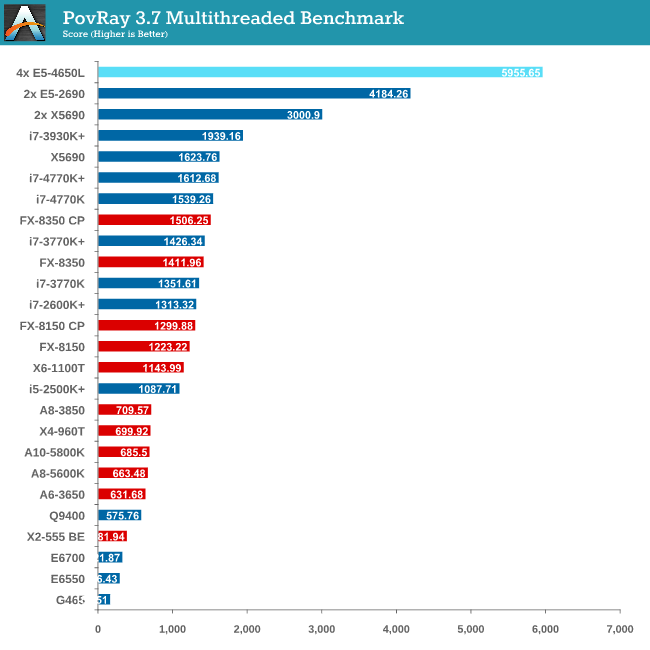
Video Conversion - x264 HD Benchmark
The x264 HD Benchmark uses a common HD encoding tool to process an HD MPEG2 source at 1280x720 at 3963 Kbps. This test represents a standardized result which can be compared across other reviews, and is dependent on both CPU power and memory speed. The benchmark performs a 2-pass encode, and the results shown are the average of each pass performed four times.
The issue with memory management and NUMA comes into effect with x264, and the complex memory accesses required over the QPI links put a dent in performance.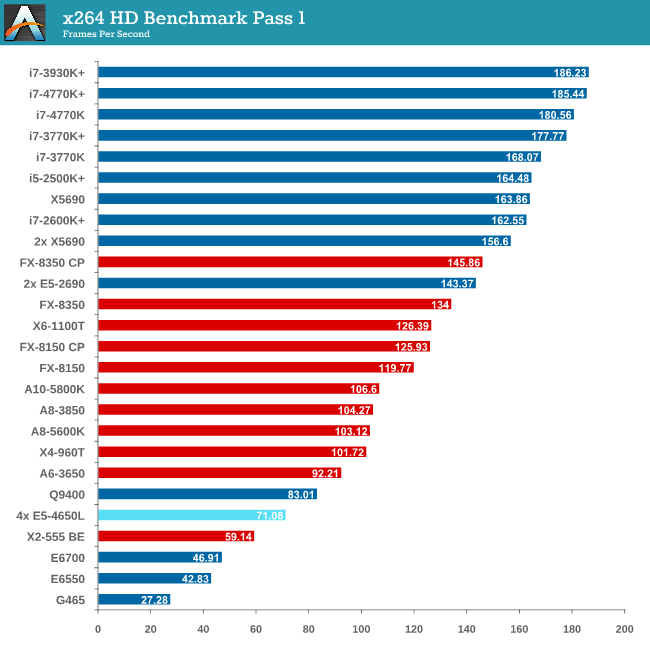
Grid Solvers - Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
It seems odd to consider that a 4P system might be detrimental to a computationally intensive benchmark, but it all boils down to learning how to code for the system you are simulating. Porting code written for a single CPU system onto a multiprocessor workstation is not a simple matter of copy-paste-done.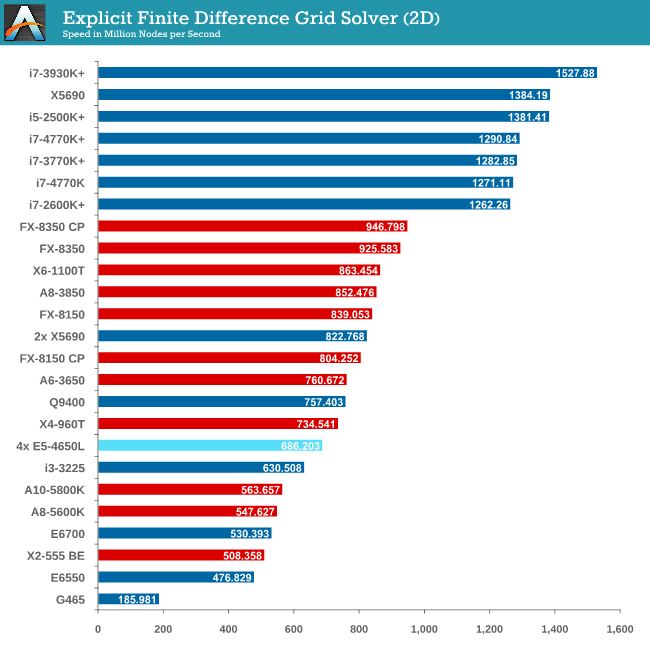
Grid Solvers - Implicit Finite Difference + Alternating Direction Implicit Method
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
Conclusions – Learn How To Code!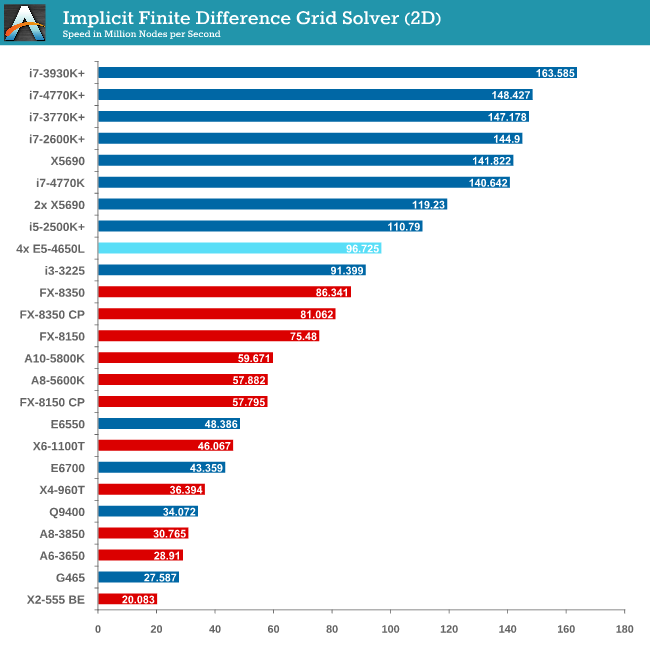
For users considering multiprocessor systems, consider your usage scenario. If your simulation contains highly independent elements and lightweight threads, then the obvious suggestion is to look at GPUs for your needs. For all other purposes it is a lot easier to consider single CPU systems but scaling may occur if we look at memory management.
This makes sense when compiling your own code – the issue gets a lot tougher when dealing with third-party software. Before spending on a large multiprocessor system, get details from the company that make your software (for which you or your institution may be paying a large amount in yearly licensing fees) about whether it is suitable for multiprocessor systems, and do not be satisfied with answers such as ‘I don’t see why not’.
With Crystalwell in the picture in the consumer space, it becomes a lot more complex when dealing with a large eDRAM/L4 cache in a multiprocessor system. The system will then need to manage the snooping protocols for larger amounts of memory, making the whole procedure a nightmare for the unfortunate team that might have to deal with it. Crystalwell makes sense in the server space for single processor systems, perhaps dealing with MPI in clusters, but it might take a while to see it in the multiprocessor world at least. Fingers crossed…!
More...
-
07-03-13, 10:30 AM #3125
Anandtech: Trials of an Intel Quad Processor System: 4x E5-4650L from SuperMicro
Trials of an Intel Quad Processor System: 4x E5-4650L from SuperMicro
In recent months at AnandTech we have tackled a few issues of dual processor systems for regular use, and whether having a dual processor system as a theoretical scientist may help or hinder various benchmark scenarios. For the problems that I encountered as a theoretical physical chemist, using a dual processor system without any form of formal training dealing with memory allocation (NUMA) resulted in a severe performance hit for anything that required a significant level of memory accesses, especially grid solvers that required pulling information from large arrays held in memory. Part of the issue was latency access dealing with data that was in the memory of the other CPU, and thus a formal training in writing NUMA code would be applicable for multi-processor systems. Nevertheless in my AnandTech testing we did see significant speedup when dealing with various ‘pre-built’ software scenarios such as video conversion using Xilisoft Video Converter, rendering using PovRay and our 3D Particle Movement Benchmark.
To take this testing one stage further, SuperMicro kindly agreed to loan me remote desktop access to one of their internal quad processor (4P) systems. The movement from 2P to 4P is almost strictly in the realms of business investment, except for a few Folding@home enthusiasts that have seen large gains moving to a quad processor AMD system using obscure buyers for motherboards and eBay for processors. But with 4P in the business realm, the software has to match that usage scenario and scale appropriately.
Our testing scenario will cover our server motherboard CPU tests only – as I only had remote desktop access I was not fortunate enough to do any ‘gaming’ tests, although our gaming CPU article may have shown that unless you are doing a massive multi-screen multi-GPU setup then anything more than a single Sandy Bridge-E system may be overkill.
Test Setup:
Supermicro X9QR7-TF+
4x Intel Xeon E5-4650L @ 2.6 GHz (3.1 GHz Turbo), 8 cores (16 threads) each
Kingston 128GB ECC DDR3-1600 C11
Windows Server Edition 2012 Standard
Issues Encountered
As you might imagine, moving from 1P to 2P and then to 4P without much experience in the field of multi-processor calculations was initially very daunting. The main issue moving to 4P was having an operating system that actually detected all the threads possible and then communicated that to software using the Windows APIs. In both Windows Server 2008 R2 Standard and 2012 Standard, the system would detect all 64 threads in task manager, but only report 32 threads to software. This raises a number of issues when dealing with software that automatically detects the number of threads on a system and only issues that number. In this scenario the user would need to manually set the number of threads, but it all depends on the way the program was written. For example, our Xilisoft and 3DPM tests do an automatic thread detection but set the threads to what is detected, whereas PovRay spawns a large number of threads despite automatic detection. Cinebench as well detected half the threads automatically, but at least has an option to spawn a custom number of threads.
Point Calculations - 3D Movement Algorithm Test
The algorithms in 3DPM employ both uniform random number generation or normal distribution random number generation, and vary in various amounts of trigonometric operations, conditional statements, generation and rejection, fused operations, etc. The benchmark runs through six algorithms for a specified number of particles and steps, and calculates the speed of each algorithm, then sums them all for a final score. This is an example of a real world situation that a computational scientist may find themselves in, rather than a pure synthetic benchmark. The benchmark is also parallel between particles simulated, and we test the single thread performance as well as the multi-threaded performance.
The 3DPM test falls under the half-thread detection issue, and as a result of the high threads but lower single core speed we only just get an improvement over a 2P Westmere-EP system. For single thread performance the single thread speed of the E5-4650L (3.1 GHz) is too low to compete with other Sandy Bridge and above processors.
Compression - WinRAR 4.2
With 64-bit WinRAR, we compress the set of files used in the USB speed tests. WinRAR x64 3.93 attempts to use multithreading when possible, and provides as a good test for when a system has variable threaded load. WinRAR 4.2 does this a lot better! If a system has multiple speeds to invoke at different loading, the switching between those speeds will determine how well the system will do.
As WinRAR is ultimately dependent on memory speed, the 1600 C11 runs into the issues that the lower memory speed situations face. Despite this, the 2P Westmere-EP system still wins hands down.
Image Manipulation - FastStone Image Viewer 4.2
FastStone Image Viewer is a free piece of software I have been using for quite a few years now. It allows quick viewing of flat images, as well as resizing, changing color depth, adding simple text or simple filters. It also has a bulk image conversion tool, which we use here. The software currently operates only in single-thread mode, which should change in later versions of the software. For this test, we convert a series of 170 files, of various resolutions, dimensions and types (of a total size of 163MB), all to the .gif format of 640x480 dimensions.
MHz and IPC wins for FastStone, which the single thread speed of the E6-4650s do not have.
Video Conversion - Xilisoft Video Converter 7
With XVC, users can convert any type of normal video to any compatible format for smartphones, tablets and other devices. By default, it uses all available threads on the system, and in the presence of appropriate graphics cards, can utilize CUDA for NVIDIA GPUs as well as AMD WinAPP for AMD GPUs. For this test, we use a set of 33 HD videos, each lasting 30 seconds, and convert them from 1080p to an iPod H.264 video format using just the CPU. The time taken to convert these videos gives us our result.
Due to the nature of XVC we do not see any speed up against Westmere-EP due to the 33rd video only being assigned a single thread, essentially doubling the time of the conversion.
Rendering – PovRay 3.7
The Persistence of Vision RayTracer, or PovRay, is a freeware package for as the name suggests, ray tracing. It is a pure renderer, rather than modeling software, but the latest beta version contains a handy benchmark for stressing all processing threads on a platform. We have been using this test in motherboard reviews to test memory stability at various CPU speeds to good effect – if it passes the test, the IMC in the CPU is stable for a given CPU speed. As a CPU test, it runs for approximately 2-3 minutes on high end platforms.
PovRay is the first benchmark that shows the full strength of 64 Intel threads, scoring almost double that of the 24 thread Westmere-EP system (which was at higher frequency).
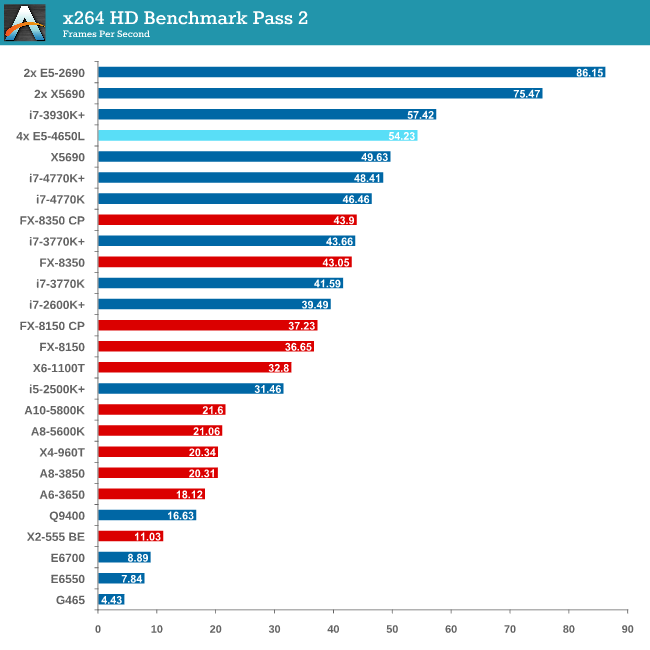
Video Conversion - x264 HD Benchmark
The x264 HD Benchmark uses a common HD encoding tool to process an HD MPEG2 source at 1280x720 at 3963 Kbps. This test represents a standardized result which can be compared across other reviews, and is dependent on both CPU power and memory speed. The benchmark performs a 2-pass encode, and the results shown are the average of each pass performed four times.
The issue with memory management and NUMA comes into effect with x264, and the complex memory accesses required over the QPI links put a dent in performance.
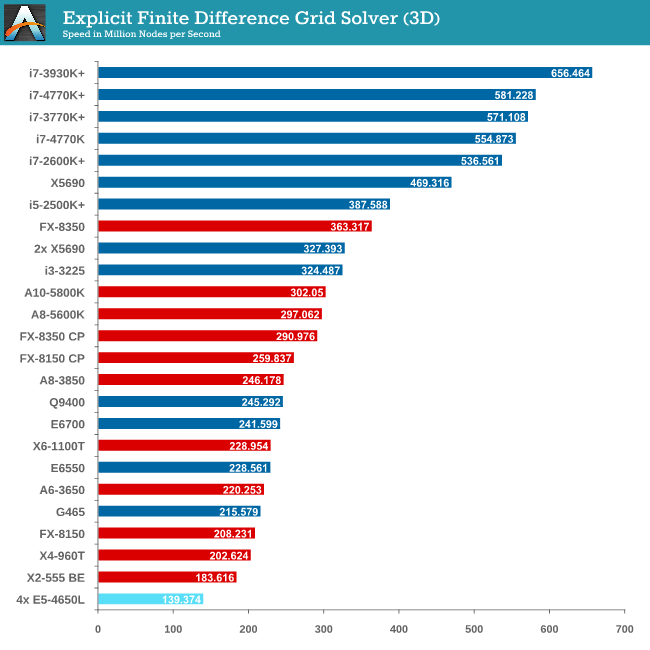
Grid Solvers - Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
It seems odd to consider that a 4P system might be detrimental to a computationally intensive benchmark, but it all boils down to learning how to code for the system you are simulating. Porting code written for a single CPU system onto a multiprocessor workstation is not a simple matter of copy-paste-done.
Grid Solvers - Implicit Finite Difference + Alternating Direction Implicit Method
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
Conclusions – Learn How To Code!
For users considering multiprocessor systems, consider your usage scenario. If your simulation contains highly independent elements and lightweight threads, then the obvious suggestion is to look at GPUs for your needs. For all other purposes it is a lot easier to consider single CPU systems but scaling may occur if we look at memory management.
This makes sense when compiling your own code – the issue gets a lot tougher when dealing with third-party software. Before spending on a large multiprocessor system, get details from the company that make your software (for which you or your institution may be paying a large amount in yearly licensing fees) about whether it is suitable for multiprocessor systems, and do not be satisfied with answers such as ‘I don’t see why not’.
With Crystalwell in the picture in the consumer space, it becomes a lot more complex when dealing with a large eDRAM/L4 cache in a multiprocessor system. The system will then need to manage the snooping protocols for larger amounts of memory, making the whole procedure a nightmare for the unfortunate team that might have to deal with it. Crystalwell makes sense in the server space for single processor systems, perhaps dealing with MPI in clusters, but it might take a while to see it in the multiprocessor world at least. Fingers crossed…!
More...
-
07-03-13, 11:31 AM #3126
Anandtech: Corsair Carbide Air 540 Case Review
Corsair's cases have been defined by excellent ease of assembly, solid watercooling support...and middling air cooling performance. The Air 540 is a completely different beast, though, and it looks like they may have sorted out that last issue.
More...
-
07-04-13, 03:31 AM #3127
Anandtech: Trials of an Intel Quad Processor System: 4x E5-4650L from SuperMicro
Trials of an Intel Quad Processor System: 4x E5-4650L from SuperMicro
In recent months at AnandTech we have tackled a few issues of dual processor systems for regular use, and whether having a dual processor system as a theoretical scientist may help or hinder various benchmark scenarios. For the problems that I encountered as a theoretical physical chemist, using a dual processor system without any form of formal training dealing with memory allocation (NUMA) resulted in a severe performance hit for anything that required a significant level of memory accesses, especially grid solvers that required pulling information from large arrays held in memory. Part of the issue was latency access dealing with data that was in the memory of the other CPU, and thus a formal training in writing NUMA code would be applicable for multi-processor systems. Nevertheless in my AnandTech testing we did see significant speedup when dealing with various ‘pre-built’ software scenarios such as video conversion using Xilisoft Video Converter, rendering using PovRay and our 3D Particle Movement Benchmark.
To take this testing one stage further, SuperMicro kindly agreed to loan me remote desktop access to one of their internal quad processor (4P) systems. The movement from 2P to 4P is almost strictly in the realms of business investment, except for a few Folding@home enthusiasts that have seen large gains moving to a quad processor AMD system using obscure buyers for motherboards and eBay for processors. But with 4P in the business realm, the software has to match that usage scenario and scale appropriately.
Our testing scenario will cover our server motherboard CPU tests only – as I only had remote desktop access I was not fortunate enough to do any ‘gaming’ tests, although our gaming CPU article may have shown that unless you are doing a massive multi-screen multi-GPU setup then anything more than a single Sandy Bridge-E system may be overkill.
Test Setup:
Supermicro X9QR7-TF+
4x Intel Xeon E5-4650L @ 2.6 GHz (3.1 GHz Turbo), 8 cores (16 threads) each
Kingston 128GB ECC DDR3-1600 C11
Windows Server Edition 2012 Standard
Issues Encountered
As you might imagine, moving from 1P to 2P and then to 4P without much experience in the field of multi-processor calculations was initially very daunting. The main issue moving to 4P was having an operating system that actually detected all the threads possible and then communicated that to software using the Windows APIs. In both Windows Server 2008 R2 Standard and 2012 Standard, the system would detect all 64 threads in task manager, but only report 32 threads to software. This raises a number of issues when dealing with software that automatically detects the number of threads on a system and only issues that number. In this scenario the user would need to manually set the number of threads, but it all depends on the way the program was written. For example, our Xilisoft and 3DPM tests do an automatic thread detection but set the threads to what is detected, whereas PovRay spawns a large number of threads despite automatic detection. Cinebench as well detected half the threads automatically, but at least has an option to spawn a custom number of threads.
Point Calculations - 3D Movement Algorithm Test
The algorithms in 3DPM employ both uniform random number generation or normal distribution random number generation, and vary in various amounts of trigonometric operations, conditional statements, generation and rejection, fused operations, etc. The benchmark runs through six algorithms for a specified number of particles and steps, and calculates the speed of each algorithm, then sums them all for a final score. This is an example of a real world situation that a computational scientist may find themselves in, rather than a pure synthetic benchmark. The benchmark is also parallel between particles simulated, and we test the single thread performance as well as the multi-threaded performance.
The 3DPM test falls under the half-thread detection issue, and as a result of the high threads but lower single core speed we only just get an improvement over a 2P Westmere-EP system. For single thread performance the single thread speed of the E5-4650L (3.1 GHz) is too low to compete with other Sandy Bridge and above processors.
Compression - WinRAR 4.2
With 64-bit WinRAR, we compress the set of files used in the USB speed tests. WinRAR x64 3.93 attempts to use multithreading when possible, and provides as a good test for when a system has variable threaded load. WinRAR 4.2 does this a lot better! If a system has multiple speeds to invoke at different loading, the switching between those speeds will determine how well the system will do.
As WinRAR is ultimately dependent on memory speed, the 1600 C11 runs into the issues that the lower memory speed situations face. Despite this, the 2P Westmere-EP system still beats the 4P but you really need a good single core system with high bandwidth memory to take advantage.
Image Manipulation - FastStone Image Viewer 4.2
FastStone Image Viewer is a free piece of software I have been using for quite a few years now. It allows quick viewing of flat images, as well as resizing, changing color depth, adding simple text or simple filters. It also has a bulk image conversion tool, which we use here. The software currently operates only in single-thread mode, which should change in later versions of the software. For this test, we convert a series of 170 files, of various resolutions, dimensions and types (of a total size of 163MB), all to the .gif format of 640x480 dimensions.
MHz and IPC wins for FastStone, which the single thread speed of the E5-4650Ls do not have.
Video Conversion - Xilisoft Video Converter 7
With XVC, users can convert any type of normal video to any compatible format for smartphones, tablets and other devices. By default, it uses all available threads on the system, and in the presence of appropriate graphics cards, can utilize CUDA for NVIDIA GPUs as well as AMD WinAPP for AMD GPUs. For this test, we use a set of 33 HD videos, each lasting 30 seconds, and convert them from 1080p to an iPod H.264 video format using just the CPU. The time taken to convert these videos gives us our result.
Due to the nature of XVC we do not see any speed up against Westmere-EP due to the 33rd video only being assigned a single thread, essentially doubling the time of the conversion.
Rendering – PovRay 3.7
The Persistence of Vision RayTracer, or PovRay, is a freeware package for as the name suggests, ray tracing. It is a pure renderer, rather than modeling software, but the latest beta version contains a handy benchmark for stressing all processing threads on a platform. We have been using this test in motherboard reviews to test memory stability at various CPU speeds to good effect – if it passes the test, the IMC in the CPU is stable for a given CPU speed. As a CPU test, it runs for approximately 2-3 minutes on high end platforms.
PovRay is the first benchmark that shows the full strength of 64 Intel threads, scoring almost double that of the 24 thread Westmere-EP system (which was at higher frequency).
Video Conversion - x264 HD Benchmark
The x264 HD Benchmark uses a common HD encoding tool to process an HD MPEG2 source at 1280x720 at 3963 Kbps. This test represents a standardized result which can be compared across other reviews, and is dependent on both CPU power and memory speed. The benchmark performs a 2-pass encode, and the results shown are the average of each pass performed four times.
The issue with memory management and NUMA comes into effect with x264, and the complex memory accesses required over the QPI links put a dent in performance.
Grid Solvers - Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
It seems odd to consider that a 4P system might be detrimental to a computationally intensive benchmark, but it all boils down to learning how to code for the system you are simulating. Porting code written for a single CPU system onto a multiprocessor workstation is not a simple matter of copy-paste-done.
Grid Solvers - Implicit Finite Difference + Alternating Direction Implicit Method
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks. Values are floating point, with memory cache sizes and speeds playing a part in the overall score.
Conclusions – Learn How To Code!
For users considering multiprocessor systems, consider your usage scenario. If your simulation contains highly independent elements and lightweight threads, then the obvious suggestion is to look at GPUs for your needs. For all other purposes it is a lot easier to consider single CPU systems but scaling may occur if we look at memory management.
This makes sense when compiling your own code – the issue gets a lot tougher when dealing with third-party software. Before spending on a large multiprocessor system, get details from the company that make your software (for which you or your institution may be paying a large amount in yearly licensing fees) about whether it is suitable for multiprocessor systems, and do not be satisfied with answers such as ‘I don’t see why not’.
With Crystalwell in the picture in the consumer space, it becomes a lot more complex when dealing with a large eDRAM/L4 cache in a multiprocessor system. The system will then need to manage the snooping protocols for larger amounts of memory, making the whole procedure a nightmare for the unfortunate team that might have to deal with it. Crystalwell makes sense in the server space for single processor systems, perhaps dealing with MPI in clusters, but it might take a while to see it in the multiprocessor world at least. Fingers crossed…!
More...
-
07-04-13, 07:31 AM #3128
Anandtech: The 2013 MacBook Air: Core i5-4250U vs. Core i7-4650U
Apple typically offers three different CPU upgrades in its portable Macs: the base CPU, one that comes with the upgraded SKU and a third BTO option that's even faster. In the case of the 2013 MacBook Air, Apple only offered two: a standard SKU (Core i5-4250U) and a BTO-only upgrade (Core i7-4650U). As we found in our initial review of the 2013 MacBook Air, the default Core i5 option ranged between substantially slower than last year's model to a hair quicker. The explanation was simple: with a lower base clock (1.3GHz), a lower TDP (15W vs. 17W) and more components sharing that TDP (CPU/GPU/PCH vs. just CPU/GPU), the default Core i5 CPU couldn't always keep up with last year's CPU.
The Core i7 CPU upgrade comes at a fairly reasonable cost: $150 regardless of configuration. The max clocks increase by almost 30%, as does the increase in L3 cache. The obvious questions are how all of this impacts performance, battery life and thermals. Finally equipped with a 13-inch MBA with the i7-4650U upgrade, I can now answer those questions. The two systems are configured almost identically, although the i7-4650U configuration includes 8GB of memory instead of 4GB. Thankfully none of my tests show substantial scaling with memory capacity beyond 4GB so that shouldn't be a huge deal. Both SSDs are the same Samsung PCIe based solution. Let's start with performance.
More...
-
07-08-13, 07:30 PM #3129
Anandtech: The Joys of 802.11ac WiFi
We’ve had quite a few major wireless networking standards over the years, and while some have certainly been better than others, I have remained a strong adherent of wired networking. I don’t expect I’ll give up the wires completely for a while yet, but Western Digital and Linksys sent me some 802.11ac routers for testing, and for the first time in a long time I’m really excited about wireless.
More...
-
07-08-13, 10:30 PM #3130
Anandtech: Android 4.2.2 Update Rollout for HTC One Begins - We Take a Look
Back when I reviewed the HTC One, I also did a walkthrough of Sense 5 and how it worked with Android 4.1.2. Although Sense 5 is a big step forwards both in visuals and functionality over its predecessor, there were still some things I wanted out of Sense and a few friction points, a number of which have been addressed in this update. Since this is undoubtably the platform that the upcoming rumored smaller and larger versions of the HTC One will run, it's worth taking a look at what's coming.
First a bit of context – HTC just recently started rolling out the Android 4.2.2 update to HTC One users in a number of regions, and our international HTC One (EMEA) just got the update, which is where we're looking at what's changed. These rollouts occur in phases and not necessarily for everyone at once, and I don't have any specific information on what regions are getting the update.
First up, there are some changes to basic functions. Widget panes can now be rearranged after their creation, though the BlinkFeed homepage remains pinned to the far left. Not a huge change, but a thankful one regardless. App shortcuts can also now be freely moved between the bottom launcher bar and widget panel by long pressing and dragging, something which shockingly enough couldn't be done before from that view.
Next, the home button gets two changes. Tapping the home button now takes you through a different, more logical flow than before. Previously pressing home after launching something from the all apps launcher view would take you back to all apps, pressing home after starting from all apps now takes you to your homepage, be it BlinkFeed or a widget pane.

The second home button change is an interesting one – HTC has added back in the ability to long press on home for a menu button. Google Now then gets activated with a swipe up from home. By default the behavior is unchanged, but if you have some applications that still haven't killed the action overflow bar and said goodbye to the menu button, this second button option is you want to use. BlinkFeed also gets a change, there's now Instagram added in as an account. Only stills work at the moment, I'm pretty sure videos just show the still preview at this point if they show up at all.

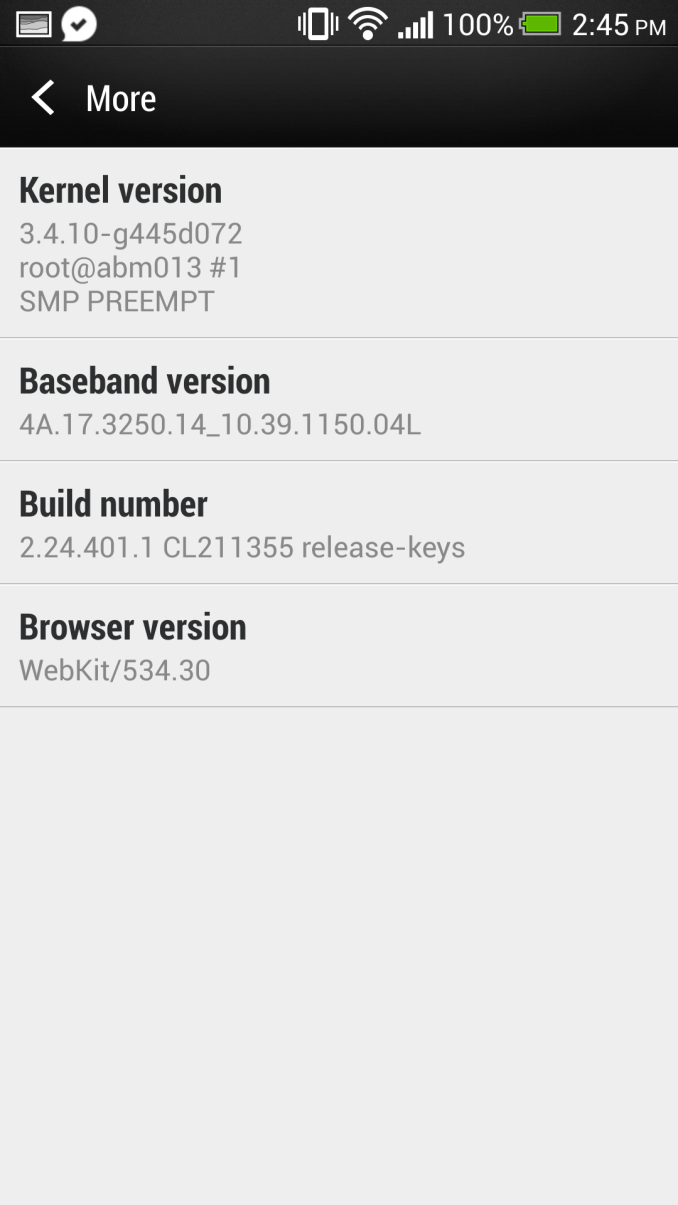
Another small but very thankful addition is I've begged every OEM for – battery percentage in the notification bar. Tap to turn it on under Power in settings, and it displays to the left of the battery visualization. You can see it in the top of basically all my screenshots. The battery percentage fuel gauging algorithm is improved as well.

Obviously a big part of Android 4.2.2 is the inclusion of the quick settings shortcuts, which you can access by doing a two finger pull down or single finger and then tapping the icon. HTC has gone and added a few extra settings shortcuts here like Screenshot, Power Saver (yay, this no longer is a persistent notification), Auto Rotate, and Wi-Fi Hotspot. In Sense 5 tapping on these toggles them, and tapping on the overflow button brings you into the appropriate settings application page.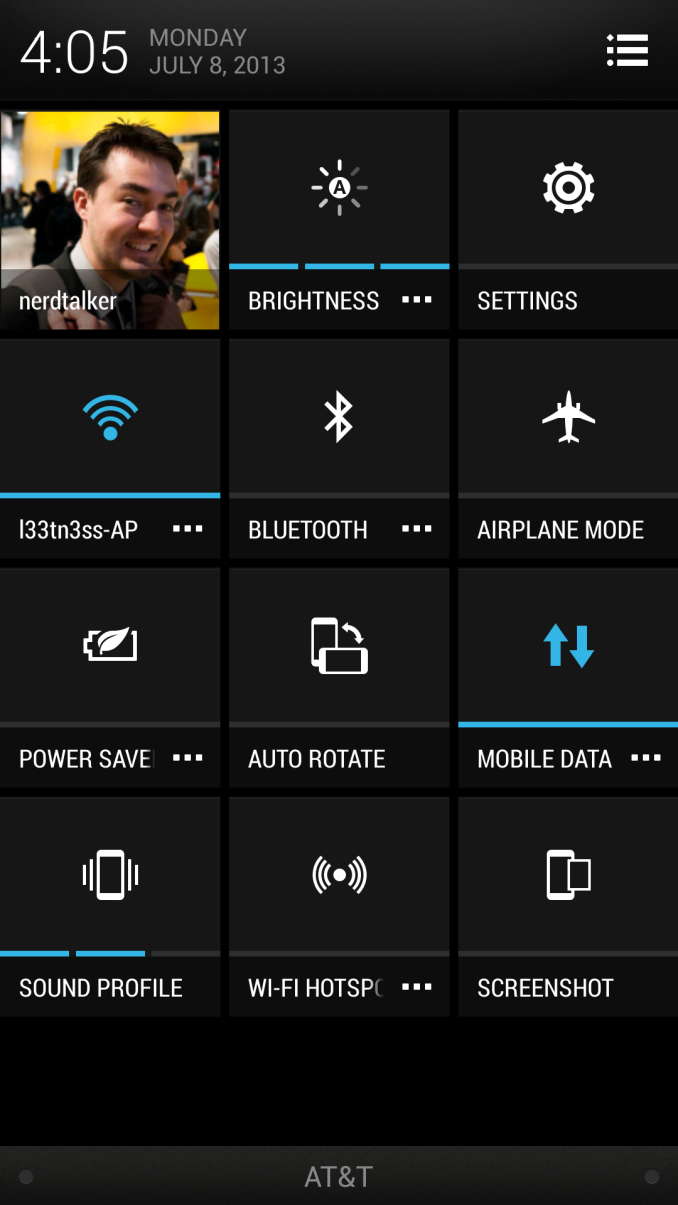

Android 4.2.2 also adds Daydreams, which is essentially a screensaver function for Android. I've never really ever used Daydream on Android 4.2.2, but it's here in the update. Also from 4.2.2 are lock screen widgets, which get included. Getting into the lock screen widgets requires going through personalize, selecting the widget lock screen style, then tapping settings to select one. You only get one widget lockscreen panel and one widget, as opposed to the 5 that stock Android gives you.


Camera gets a number of thankful additions and tweaks. I've wanted this from HTC's camera app for a long time now – AE/AF lock, and it's here. Long press anywhere in the preview, and after a few seconds AF/AE (Auto Focus and Auto Exposure) are locked until you tap to re-focus and re-expose again. One more thing I still want is the UI camera button to take the picture on tap release instead of on tap press, but maybe that'll come eventually.
Another very thankful change is the way Zoes are recorded. There's now just one JPG and one MP4 in the folder for a Zoe, instead of the 20 JPGs and one MP4 for the previous system. The full size photo of your choice can still be pulled out and saved with the same UI, they're just not all dumped into DCIM every time, just the default one, or the one of your choice. I'm not sure where the full size images are being stored, but they're still somewhere.
In the Gallery there's one less view now, tapping the gallery gets you immediately into Events view. A big one everyone wanted also was the inclusion of more highlights reel themes. There are now six new highlights reel themes, for a total of 12. There's also a new easier way to select custom content for a highlights reel.
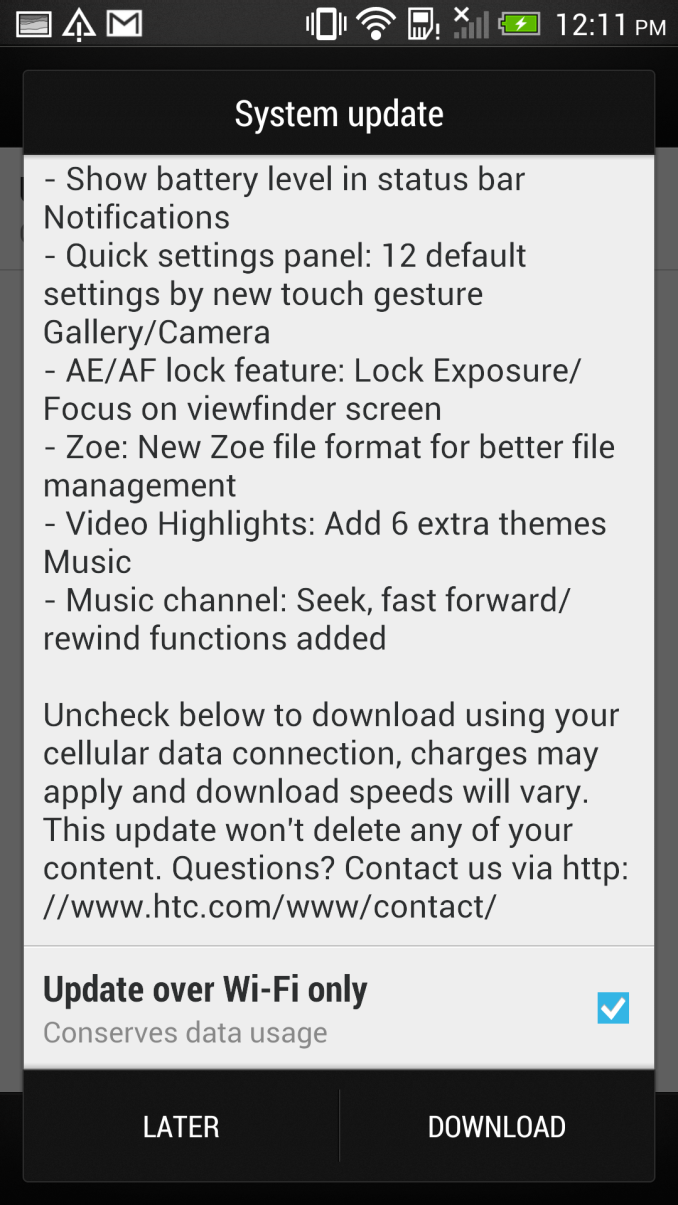
So that wraps up the big changes in this 416.46 MB OTA update for the international variants of the HTC One. The update is again rolling out on a region by region variant, as always there's that operator overhead to think about for the USA, no word on specifics at this point.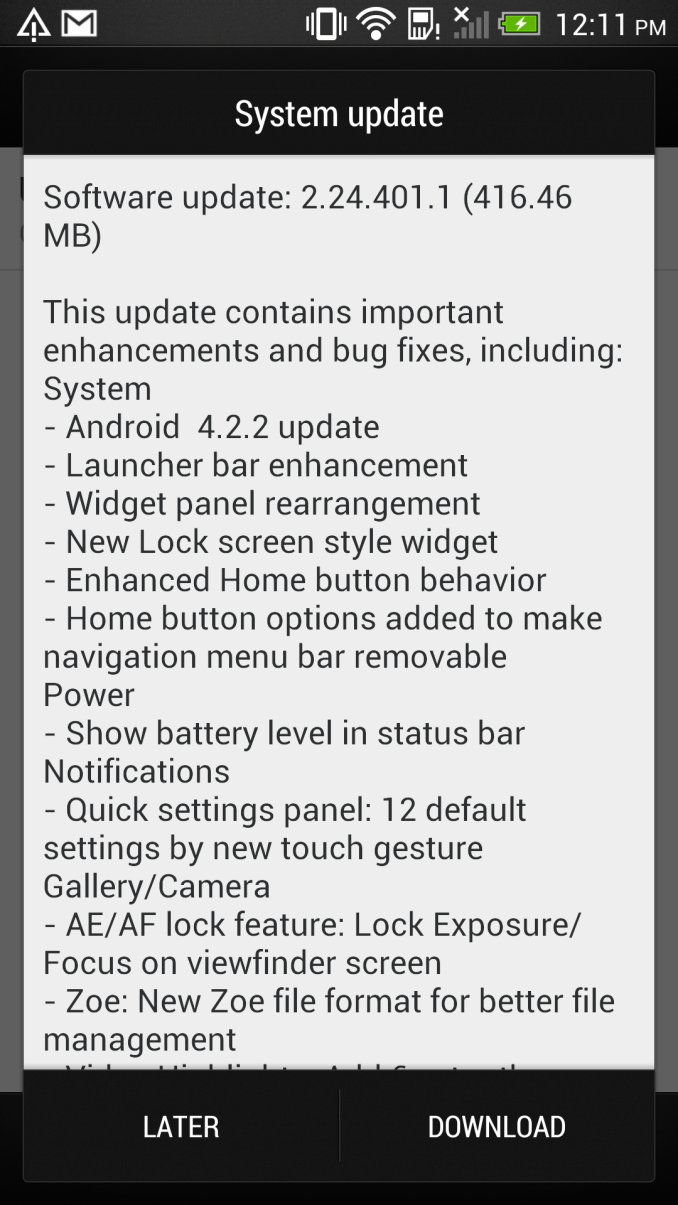
More...



 Quote
QuoteThread Information
Users Browsing this Thread
There are currently 13 users browsing this thread. (0 members and 13 guests)















Bookmarks